
你准备好迎接与数字人共生的赛博朋克世界了吗?
作为构建未来虚拟世界诸多应用的主干,如何创造栩栩如生的虚拟数字人,一直是计算机视觉、计算机图形学与多媒体等人工智能相关学科密切关注的重要研究课题。
近日,中国科学技术大学联合的卢深视科技有限公司、浙江大学与清华大学共同打造的AD-NeRF技术,引发了学界及业界关注。
来自中科大张举勇课题组等机构的研究者们在近期大火的神经辐射场(NeRF: Neural Radiance Fields)技术基础上,提出了一种由语音信号直接生成说话人视频的算法。仅需要目标人物几分钟的说话视频,该方法即可实现对该人物超级逼真的形象复刻和语音驱动。
论文地址:
https://arxiv.org/pdf/2103.11078.pdf
项目地址:
https://yudongguo.github.io/ADNeRF/
「让虚拟人构建变得触手可及」
随着人工智能技术走向沉稳落地,转型探索新技术在社会中的实际应用,已经成为学术和工业界普遍达成的共识。在这一过程中,「数字虚拟人」无疑是主流视野下非常「吸睛」的一个概念。按照目标角色最终的呈现形态分类,数字虚拟人可以分为 2D 和 3D 类型,或是动漫、拟人和真实人物等种类。2021 年春晚,虚拟偶像洛天依首次被呈现在全国人民阖家团圆时刻的电视晚会舞台上。三月两会,央视网打造的数字虚拟记者「小 C」,则以生动的角色形象,承担起了同人大代表们实时连线,播报政策新闻的任务。



从上到下依次为三星虚拟数字人 Neon、虚拟偶像洛天依、电影角色阿丽塔。
据爱奇艺早前发布的《2019 虚拟偶像观察报告》,当今中国至少有 3.9 亿人正在关注虚拟偶像。在抖音、快手和 B 站等各大短视频平台上,至少活跃着上万名数字虚拟人主播。不仅在泛娱乐领域,数字虚拟人还为其他一系列社会化应用提供了广阔的想象空间:虚拟医生、虚拟教师、虚拟客服、虚拟导购等等。
作为人机交互的重要媒介,如何高效构建虚拟人逼真的外表形象、自然的神态与动作,一直是该领域备受关注的研究热点。其中,基于传统计算机图形学与动画制作技术,构建生动且逼真的虚拟人行为动态(如与语音内容符合的嘴型与表情等)需要专业且复杂的人力工作,这大大限制了虚拟数字人的广泛应用。近年来,基于深度学习方法的虚拟人构建技术取得了较好的突破。然而,现有基于学习的方法中,无论是基于图像的生成对抗网络(GAN)方法,还是基于三维人脸重建模型的人脸编辑 - 渲染方法,存在依赖大量训练数据、生成结果质量不佳等问题。以 2017 年 Suwajanakorn 等人提出的 SynthesizingObama 工作为例,为了实现针对奥巴马单一角色的语音驱动,该方法使用了奥巴马本人高达 14 个小时的视频训练数据,才能保证最终较好的图像和视频效果。而众多基于 GAN 的人脸语音驱动工作,则受限于 GAN 模型本身的训练复杂度,通常只能输出不超过 256x256 分辨率的视频结果。
基于 GAN 的方法生成图像分辨率低,而基于神经辐射场渲染的 AD-NeRF 支持任意分辨率渲染。
在 AD-NeRF 方法中,仅需要目标人物三至五分钟的说话视频,即可实现任意语音驱动该人物的效果。不仅如此,其生成结果具有高清的图像质量和自然的面部神态,更是远胜于此前的方法。这种「价廉物美」的方法,仅需要少量训练数据即能生成高质量的最终结果,无疑是为创造虚拟人形象提供了一个强大且便捷的工具。
人脸魔术是如何做到的?
下面的示例图显示了 AD-NeRF 工作的算法流程框架:
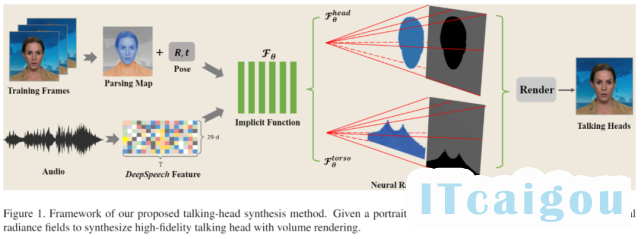
(1)语音到动态神经辐射场的跨模态映射:为了刻画说话人脸、躯干以及背景的高质量细节与动态,作者们将 DeepSpeech 语音特征同最新的神经辐射场方法(NeRF)相结合,即建模一个隐式函数 F,其输入包括假设的相机位置,视线方向,以及对应的语音特征,输出沿每条射线上连续位点的颜色与密度值,通过沿射线积分,确定该射线指向的像素点的最终颜色值。
(2)完整、稳定的头部与身体躯干合成:针对人脸说话过程中脸部与躯干运动并非完全统一的现象,作者们将原始的神经辐射场模型拆分成了两个各自分工的隐式模型表示。首先,他们对训练数据中每帧图像进行了语义分割,其中人脸部分使用多帧连续光流估计出三维运动参数,直接转换为假设的相机外参,用于训练针对人头部分的神经辐射场。而身体模块,则在人头模型的基础上,将人头运动参数作为额外的条件信息,用于控制身体部分的建模。这一设计带来的明显好处是解决了头部 - 身体姿态不一致带来的抖动效应:

(3)支持背景与视角编辑:由于神经辐射场所刻画的隐式三维信息,作者们还进一步探索了任意替换背景和改变观测角度的后续应用。而要实现这些应用,只需要在输入测试音频的同时,改变假设的相机外参以及背景图片即可。这些应用的示例可参见下图:

AD-NeRF 带来了哪些可能性?
曾几何时,数字人还是一个备受科幻小说和电影喜爱的赛博朋克题材;如今,随着一项项数字虚拟人创作技术的迭代更新,这一充满未来感的概念正以前所未有的速度走入寻常百姓家。那么,AD-NeRF 究竟会给哪些实际的虚拟人应用带来技术上的可能性呢?
首先是在视频会议领域,正如上文中所展示的一样,AD-NeRF 可以轻松支持对任意人物形象的语音驱动。对于带宽需求较大的视频会议应用而言,可能将不再需要实时传输视频的编解码信号,而只需音频信号即驱动说话人本身的虚拟形象。而 AD-NeRF 所支持的背景替换和姿态编辑,搭配起 AR 头盔等设备,更是可以让你恍如身临其境一般,在一个可以任意创作的三维情景中同对方对话。
其次,由于 AD-NeRF 仅仅需要几分钟的视频用于训练特定人物形象的动态辐射场。假如你想留下某个至亲好友的数字形象,永远能够同他面对面交流,那么 AD-NeRF 的算法设计,将大大简化这个数字形象的制作难度——在赛博空间永生或许不再是一场梦。
最后,AD-NeRF 对于改善当前商用的数字虚拟人搭建流程,无疑具有强大的潜力。无论是创造逼真的虚拟主播,亲切的虚拟导购,或是严肃的虚拟教师等等,AD-NeRF 都可以「手到擒来」。只需要一个表现力丰富的演员录制一段语音视频,剩下的就可以交给自动化的语音驱动技术了,其在商业创新上的应用前景非常广阔。
在拥有强大技术赋能的同时,另一方面,越来越低的门槛和数据需求也让数字虚拟人的创作面临着诸多风险与争议。比如用假冒的数字形象盗取他人的财产或者伪造视频散布虚假新闻,甚至是用于故意贬损他人侮辱人格等现象。去年,以 DeepFake、Zao 等一系列「AI 换脸」的人工智能应用,就曾经引发了全社会基于道德和隐私层面广泛的讨论,相应的,在学术界也催生了一系列以 DeepForensics 为主题的「换脸检测」研究。
现在,AD-NeRF 从应用层面以一种更为高级的底层算法,即通过神经辐射场隐式地建模三维运动细节,渲染了完整且逼真的图片帧,对于真假人脸视频的判别和检测,也提出了更有价值的挑战。
「魔高一尺,道高一丈」,出于安防和隐私保护的需求,更多强大的防伪和检测算法在未来势必与虚拟人技术一道,成为共同竞技和发展的双子星。站在公平与正义的角度,虚拟人这一数字时代的产物,同样需要被纳入法律法规和行业条例的约束之中。相信在未来,虚拟数字人将成为智能方便可信赖的代名词,为改善这个世界的信息交流与人际互动提供更大的帮助。



