
在近来研究人员热衷于探索 Transformer 用于目标检测的尝试时,这篇论文提出了一种全新的观点,即利用全卷积网络也可以实现良好的端到端目标检测效果。
目标检测是计算机视觉领域的一个基础研究主题,它利用每张图像的预定义类标签来预测边界框。大多数主流检测器使用的是基于锚的标签分配和非极大值抑制(NMS)等手动设计。近来,很多研究者提出方法通过距离感知和基于分布的标签分类来消除预定义的锚框集。尽管这些方法取得了显著的进展和优越的性能,但抛弃手动设计的 NMS 后处理可能阻碍完全的端到端训练。
基于这些问题,研究人员相继提出了 Learnable NMS、Soft NMS 和 CenterNet 等,它们能够提升重复删除效果,但依然无法提供有效的端到端训练策略。之后,Facebook AI 研究者提出的 DETR 将 Transformer 用到了目标检测任务中,还取得了可以媲美 Faster R-CNN 的效果。但是,DETR 的训练时间却大大延长,在小目标上的性能也相对较低。
所以,在本文中,来自旷视科技和西安交通大学的研究者提出了一个新颖问题:全卷积网络是否可以实现良好的端到端目标检测效果?并从标签分配和网络架构两个方面回答并验证了这一问题。

论文链接:https://arxiv.org/pdf/2012.03544.pdf
项目代码:https://github.com/Megvii-baseDetection/DeFCN (内部代码迁移 + 审查中,后续放出)
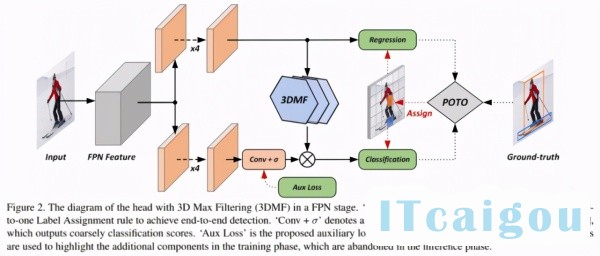
具体而言,研究者基于 FCOS,首次在 dense prediction 上利用全卷积结构做到 E2E,即无 NMS 后处理。研究者首先分析了常见的 dense prediction 方法(如 RetinaNet、FCOS、ATSS 等),并且认为 one-to-many 的 label assignment 是依赖 NMS 的关键。受到 DETR 的启发,研究者设计了一种 prediction-aware one-to-one assignment 方法。
此外,研究者还提出了 3D Max Filtering 以增强 feature 在 local 区域的表征能力,并提出用 one-to-many auxiliary loss 加速收敛。本文方法基本不修改模型结构,不需要更长的训练时间,可以基于现有 dense prediction 方法平滑过渡。本文方法在无 NMS 的情况下,在 COCO 数据集上达到了与有 NMS 的 FCOS 相当的性能;在代表了密集场景的 CrowdHuman 数据集上,本文方法的 recall 超越了依赖 NMS 方法的理论上限。
整体方法流程如下图所示:
One-to-many vs. one-to-one
自 anchor-free 方法出现以来,NMS 作为网络中最后一个 heuristic 环节,一直是实现 E2E dense prediction 的最大阻碍。但其实可以发现,从 RPN、SSD、RetinaNet 等开始,大家一直遵循着这样一个流程:先对每个目标生成多个预测(one-to-many),再将多个预测去重(many-to-one)。所以,如果不对前一步 label assignment 动刀,就必须要保留去重的环节,即便去重的方法不是 NMS,也会是 NMS 的替代物(如 RelationNet,如 CenterNet 的 max pooling)。
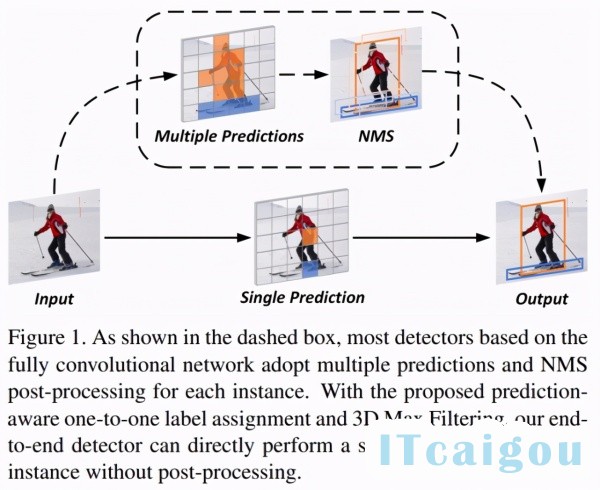
那直接做 one-to-one assignment 的方法是否存在呢?其实是有的。上古时代有一个方法叫 MultiBox,对每个目标和每个预测做了 bipartite matching,DETR 其实就是将该方法的网络换成了 Transformer。此外还有一个大家熟知的方法:YOLO,YOLO 也是对每个目标只匹配一个 grid[1] ,只不过它是采用中心点做的匹配,而且有 ignore 区域。
Prediction-aware one-to-one
于是接下来的问题就是,在 dense prediction 上能不能只依赖 one-to-one label assignment,比较完美地去掉 NMS?研究者首先基于去掉 centerness 分支的 FCOS,统一网络结构和训练方法,用 Focal Loss + GIoU Loss,做了如下分析实验:
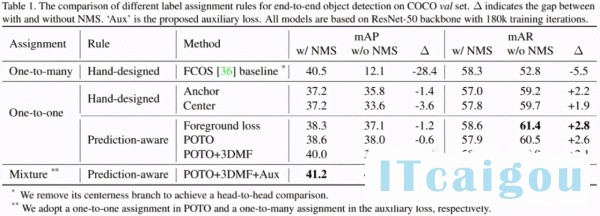
研究者设计了两种 hand-crafted one-to-one assignment 方法,分别模仿 RetinaNet(基于 anchor box)和 FCOS(基于 center 点),尽可能做最小改动,发现已经可以将有无 NMS 的 mAP 差距缩小到 4 个点以内。
但研究者认为手工设计的 label assignment 规则会较大地影响 one-to-one 的性能,比方说 center 规则对于一个偏心的物体就不够友好,而且在这种情况下 one-to-one 规则会比 one-to-many 规则的鲁棒性更差。所以认为规则应该是 prediction-aware 的。研究者首先尝试了 DETR 的思路,直接采用 loss 做 bipartite matching 的 cost[2] ,发现无论是绝对性能还是有无 NMS 的差距,都得到了进一步的改善。
但他们知道,loss 和 metrics 往往并不一致,它常常要为优化问题做一些妥协(比如做一些加权等等)。也就是说,loss 并不一定是 bipartite matching 的最佳 cost。因而研究者提出了一个非常简单的 cost:

看起来稍微有点复杂,但其实就是用网络输出的 prob 代表分类,网络输出和 gt 的 IoU 代表回归,做了加权几何平均,再加一个类似于 inside gt box 的空间先验。加权几何平均和空间先验在后面都分别做了 ablation。
这就是研究者提出的 POTO 策略,它进一步地提升了无 NMS 下的性能,也侧面验证了 loss 并不一定是最好的 cost[3]。但从 Table 1 中也发现了,POTO 的性能依旧不能匹敌 one-to-many+NMS 组合。研究者认为问题出在两个方面:
one-to-one 需要网络输出的 feature 非常 sharp,这对 CNN 提出了较严苛的要求(这也是 Transformer 的优势);
one-to-many 带来了更强的监督和更快的收敛速度。
于是分别用 3D Max Filtering 和 one-to-many auxiliary loss 缓解如上问题。
3D Max Filtering
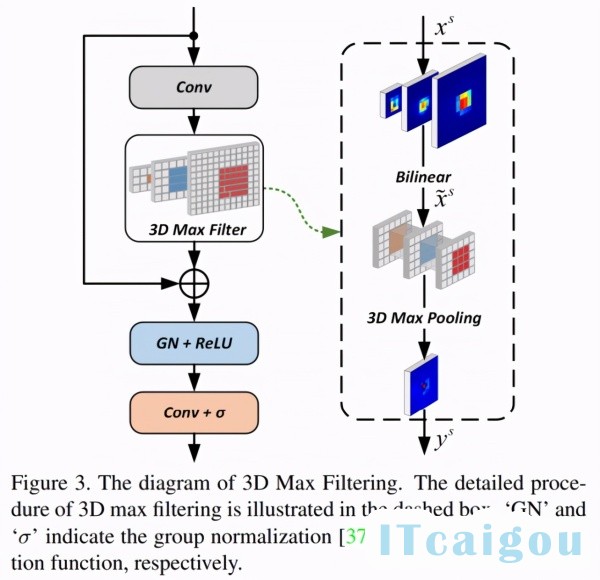
如 Figure 3 所示,这个模块只采用了卷积、插值、max pooling 3d,速度非常快,也不需要写 cuda kernel。
One-to-many auxiliary loss
针对第二点监督不够强、收敛速度慢,研究者依旧采用 one-to-many assignment 设计了 auxiliary loss 做监督,该 loss 只包含分类 loss,没有回归 loss。assignment 本身没什么可说的,appendix 的实验也表明多种做法都可以 work。这里想提醒大家的是注意看 Figure 2 的乘法,它是 auxiliary loss 可以 work 的关键。在乘法前的一路加上 one-to-many auxiliary loss,乘法后是 one-to-one 的常规 loss。由于 1*0=0,1*1=1,所以只需要大致保证 one-to-one assignment 的正样本在 one-to-many 中依然是正样本即可。
实验
最主要的实验结果已经在 Table 1 中呈现了,此外还有一些 ablation 实验。
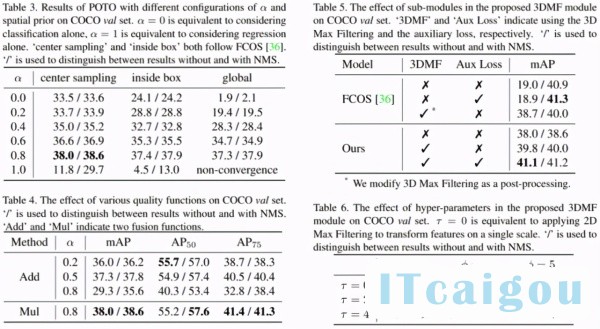
这里 highlight 几点:
α越低,分类权重越大,有无 NMS 的差距越小,但绝对性能也会降低 [4];α太高也不好,后续所有实验用α=0.8;
在α合理的情况下,空间先验不是必须的,但空间先验能够在匹配过程中帮助排除不好的区域,提升绝对性能;研究者在 COCO 实验中采用 center sampling radius=1.5,在 CrowdHuman 实验中采用 inside gt box[5];
加权几何平均数(Mul)[6]比加权算术平均数(Add)[7]更好。
去掉 NMS 的最大收益其实是 crowd 场景,这在 COCO 上并不能很好地体现出来。所以又在 CrowdHuman 上做了实验如下:
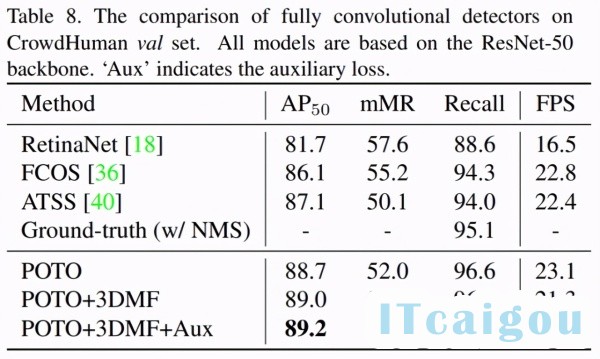
请注意 CrowdHuman 的 ground-truth 做 NMS threshold=0.6,只有 95.1% 的 Recall,这也是 NMS 方法的理论上限。而本文方法没有采用 NMS,于是轻易超越了这一上限。
研究者还做了其它一些实验和分析,欢迎看原文。
可视化
经过以上改进,研究者成功把 one-to-one 的性能提升到了与 one-to-many+NMS 方法 comparable 的水平。此外还可视化了 score map,可以发现 FCN 是有能力学出非常 sharp 的表示的,这也是很让研究者惊奇的一点。
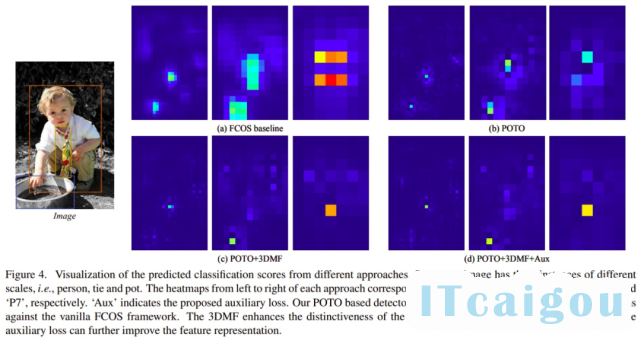
结果图中比较明显的改善出现在多峰 case 上。比如两个物体有一定的 overlap(但又没有特别重合),这个时候 one-to-many+NMS 方法经常出现的情况是,除了两个物体分别出了一个框之外,在两个物体中间也出了一个框,这个框与前两个框的 IoU 不足以达到 NMS threshold,但置信度又比较高。这类典型的多峰问题在 POTO 中得到了较大的缓解。

Others
有些人可能比较关心训练时间,因为潜意识里在 dense prediction 上做 bipartite matching 应该是很慢的。然而实际上依赖于 scipy 对 linear_sum_assignment 的优化,实际训练时间仅仅下降了 10% 左右。
如果对这一时间依然敏感,可以用 topk(k=1)代替 bipartite matching;在 dense prediction 里 top1 实际上是 bipartite matching 的近似解 [8] 。相似地,k>1 的情况对应了 one-to-many 的一种新做法,研究者也对此做了一些工作,后续可能会放出来。
参考
如果有人感兴趣的话,可以在 YOLO 上去掉 NMS 尝试一下,可以接近 30mAP。
注意这里没有使用 DETR 的 CE+GIoU+L1 组合,而是直接采用 loss 本身(Focal+GIoU)。研究者认为这样更符合 DETR 用 loss 做 cost 的原意。
其实这里可以有一个脑洞留给大家,因为 cost 是不需要求导的,所以甚至是可以直接算 AP 当 cost 的。
侧面印证了分类和回归的冲突在检测任务上是显著的。
理由很简单,CrowdHuman 的遮挡问题太严重,center 区域经常完全被遮挡。
事实上加权几何平均数的负对数就是 CE+IoU Loss,加权算术平均数则没有明显的物理含义。
NoisyAnchor 在 assign 中采用了类似的公式,只不过采用的是 anchor IoU。
更具体来讲,top1(即 argmin)是 Hugarian Algorithm 只做第一次迭代的结果;由于在 dense prediction 下冲突会很少,一次迭代就已经逼近了最优匹配,这也是为什么 Hungarian Algorithm 这里实际运行很快。



