
IT采购网4月19日消息,微软的最新研究预览版模型虽然暂时只能供微软研究团队使用,但所展示的功能令人印象深刻。这款模型被称为VASA-1,它采用了一种全新的框架,用于创造逼真的说话人脸,特别适用于虚拟人物的动画制作。与之前类似技术相比,VASA-1在质量和逼真度上似乎有了质的飞跃,能够减少嘴部动作的伪影,与Google研究院最近推出的VLOGGER人工智能模型类似。
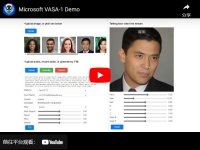
据IT采购网了解,VASA-1的工作原理是利用音频驱动动画的方法,可以根据音频内容生成相应的面部表情和动作。微软表示,该模型不仅能够处理面向正面的人像图像,还能应对不同方向拍摄的图像,表现出强大的控制能力,包括眼睛注视的方向、头部距离甚至情绪。
VASA-1的意义在于,它拓展了许多领域的应用可能性。例如,可以用于游戏中的高级唇语同步,提升游戏的沉浸感;也可用于社交媒体视频的虚拟化身创建,以及基于人工智能的电影制作,使人工智能角色看起来更加逼真。

然而,尽管VASA-1展示了出色的效果,微软团队表示,目前这只是一次研究演示,并没有公开发布的计划,也不会提供给开发人员在产品中使用。
该模型令人惊讶的一点是,即使在训练数据集中没有包含音乐内容,它也能完美地对歌曲进行歌词嘴型同步,展示出出色的多功能性。它还能处理不同风格的图像,包括蒙娜丽莎。
虽然微软团队强调VASA-1目前仅用于研究,但人们对它未来的潜在应用充满期待,甚至可能成为未来一些产品的一部分。



