
前言
近期,meta 宣布大语言模型 Llama2 开源,包含7B、13B、70B不同尺寸,分别对应70亿、130亿、700亿参数量,并在每个规格下都有专门适配对话场景的优化模型Llama-2-Chat。Llama2 可免费用于研究场景和商业用途(但月活超过7亿以上的企业需要申请),对企业和开发者来说,提供了大模型研究的最新利器。
目前,Llama-2-Chat在大多数评测指标上超过了其他开源对话模型,并和一些热门闭源模型(ChatGPT、PaLM)相差不大。阿里云机器学习平台PAI第一时间针对 Llama2 系列模型进行适配,推出全量微调、Lora微调、推理服务等场景最佳实践,助力AI开发者快速开箱。以下我们将分别展示具体使用步骤。
最佳实践一:Llama 2 低代码 Lora 微调及部署
本实践将采用阿里云机器学习平台PAI-快速开始模块针对 Llama-2-7b-chat 进行开发。PAI-快速开始支持基于开源模型的低代码训练、布署和推理全流程,适合想要快速开箱体验预训练模型的开发者。
一、准备工作
1、进入PAI-快速开始页面
a. 登入PAI控制台 https://pai.console.aliyun.com/
b. 进入PAI工作空间,并在左侧导航栏中找到“快速开始”。
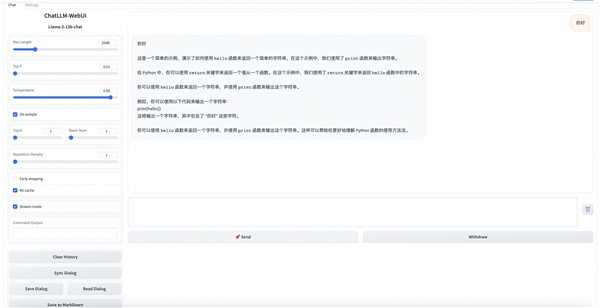
2、选择Llama2模型
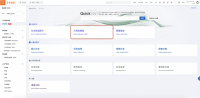
PAI-快速开始包含了不同来源的许多热门开源模型,来支持人工智能的不同领域和任务。在本次实例中,请选择“生成式AI-大语言模型(large-language-model)”,进入模型列表页。
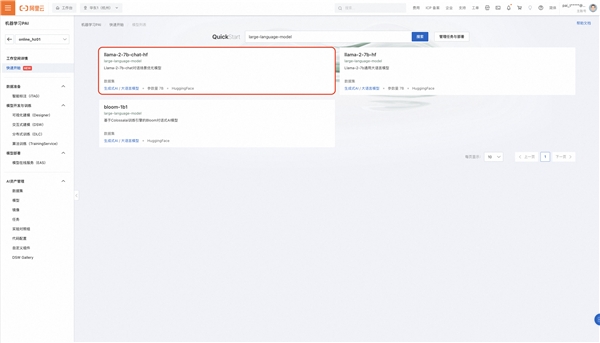
在模型列表页中您可以看到多个来自不同开源社区的主流模型。在本次展示中,我们将使用llama-2-7b-chat-hf模型(llama-2-7b-hf模型同理)。您也可以自由选择其他适合您当前业务需求的模型。
Tips:
一般来说,参数量越大的模型效果会更好,但相对应的模型运行时产生的费用和微调训练所需要的数据量都会更多。Llama-2-13B和70B的版本,以及其他开源大语言模型也将后续在PAI-快速开始上线,敬请期待。
二、模型在线推理
快速开始提供的llama-2-7b-chat-hf来源于HuggingFace提供的Llama-2-7b-chat模型,它也是主要基于Transformer架构的大语言模型,使用多种混合的开源数据集进行训练,因此适合用于绝大多数的英文非专业领域场景。我们可以通过PAI快速开始将此模型直接部署到PAI-EAS,创建一个推理服务。
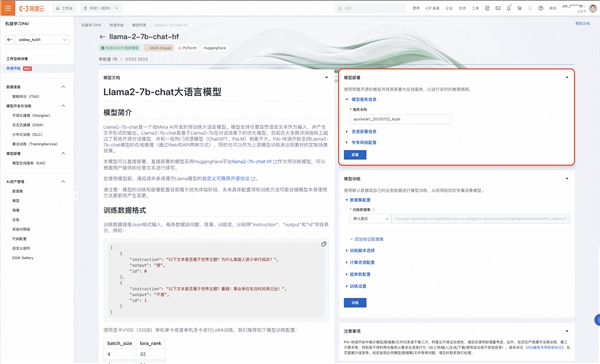
1、部署模型
通过模型详情页面的的部署入口您可以一键创建一个基于此模型的在线推理服务,所有的参数已经帮您默认配置完毕。当然,您也可以自由选择所使用的计算资源和其他设置,我们即可以将该模型直接部署到PAI-EAS创建推理服务。
请注意,模型需要至少64GiB内存和24GiB及以上的显存,请确保您选择的计算资源满足以上要求,否则部署可能失败。
通过服务详情页,您可以查看推理服务的部署状态。当服务状态为“运行中”时,表示推理服务已经部署成功。
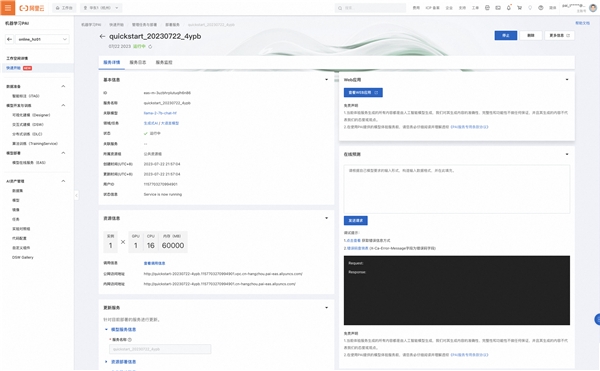
Tips:
后续您可以随时在PAI-快速开始中点击“管理任务与部署”按钮来回到当前的推理服务。
2、调用推理服务
在部署成功之后,您即可通过WebUI的方式来最快速度调试您的服务,发送预测请求。
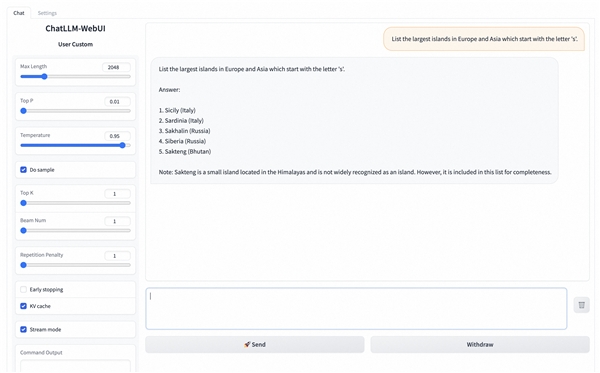
在WebUI中也同时支持了API调用能力,相关文档可以在WebUI页底点击“Use via API”查看。
三、模型微调训练
llama-2-7b-chat-hf模型适用于绝大多数非专业的场景。当您需要应用特定领域的专业知识时,您可以选择使用模型的微调训练来帮助模型在自定义领域的能力。
Tips:
大语言模型也可以在对话过程中直接学习到比较简单的知识,请根据自己的需求选择是否训练。当前快速开始支持的训练方式基于LoRA。LoRA训练相较于其他训练方式(如SFT等)会显著降低训练成本和时间,但大语言模型的LoRA训练效果可能不稳定。
1、准备数据
Tips:
为方便您试用体验Llama 2模型,我们在 llama-2-7b-chat-hf的模型卡片中也已经帮您准备了一份默认用于Instruction Tuning的数据集来直接进行微调训练。
模型支持使用OSS上的数据进行训练。训练数据接受Json格式输入,每条数据由问题、答案、id组成,分别用"instruction"、"output"和"id"字段表示,例如:
[
{
"instruction": "以下文本是否属于世界主题?为什么美国人很少举行阅兵?",
"output": "是",
"id": 0
},
{
"instruction": "以下文本是否属于世界主题?重磅!事业单位车改时间表已出!",
"output": "不是",
"id": 1
}
]
训练数据的具体格式也可以在PAI-快速开始的具体模型介绍页中查阅。
关于如何上传数据到OSS,以及查看相应的数据,请参考OSS的帮助文档:https://help.aliyun.com/document_detail/31883.html?spm=a2c4g.31848.0.0.71102cb7dsCgz2
为了更好的验证模型训练的效果,除了提供训练数据集之外,也推荐您准备一份验证数据集:它将会用于在训练中评估模型训练的效果,以及训练的参数优化调整。
2、提交训练作业
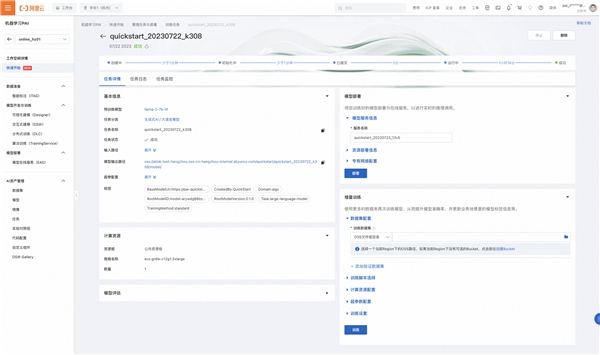
在准备好使用的数据集之后,您即可以在快速开始的模型页面配置训练使用的数据集、提交训练作业。我们已经默认配置了优化过的超参数和训练作业使用的计算资源配置,您也可以根据自己的实际业务修改。
通过训练作业详情页,您可以查看训练任务的执行进度、任务日志、以及模型的评估信息。当训练任务的状态为“成功”,训练作业产出的模型会被保存到OSS上(见作业详情页的“模型输出路径”)。
Tips:
使用默认数据集和默认超参数、计算资源训练大概预计的完成时间在1小时30分钟左右。如果使用自定义训练数据和配置项,预计的训练完成时间可能有所差异,但通常应该在数小时后完成。如果中途关闭了页面,您可以随时在PAI-快速开始中点击“管理任务与部署”按钮来回到当前的训练任务。
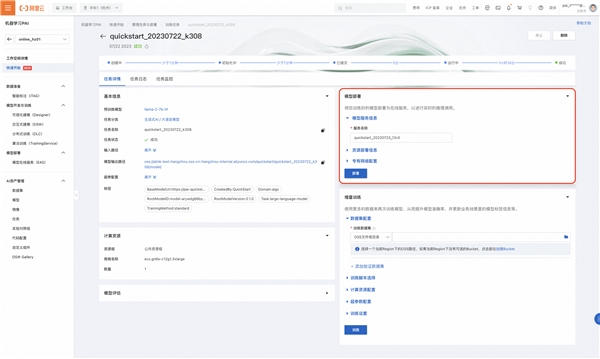
3、部署微调模型
当微调训练成功之后,用户可以直接在作业详情页将获得的模型部署为推理服务。具体的模型部署和服务调用流程请参照以上的“直接部署模型”的文档。
最佳实践二:Llama2 全参数微调训练
? 本实践将采用阿里云机器学习平台PAI-DSW模块针对 Llama-2-7B-Chat 进行全参数微调。PAI-DSW是交互式建模平台,该实践适合需要定制化微调模型,并追求模型调优效果的开发者。
一、运行环境要求
Python环境3.9以上,GPU推荐使用A100(80GB),该资源比较紧俏,建议多刷新几次。
二、准备工作
1、登入PAI并下载 Llama-2-7B-Chat
a. 登入PAI控制台 https://pai.console.aliyun.com/
b. 进入 PAI-DSW 创建实例后下载模型文件。运行如下代码,可以自动为您选择合适的下载地址,并将模型下载到当前目录。
import os
dsw_region = os.environ.get("dsw_region")
url_link = {
"cn-shanghai": "https://atp-modelzoo-sh.oss-cn-shanghai-internal.aliyuncs.com/release/tutorials/llama2/llama2-7b.tar.gz",
"cn-hangzhou": "https://atp-modelzoo.oss-cn-hangzhou-internal.aliyuncs.com/release/tutorials/llama2/llama2-7b.tar.gz",
"cn-shenzhen": "https://atp-modelzoo-sz.oss-cn-shenzhen-internal.aliyuncs.com/release/tutorials/llama2/llama2-7b.tar.gz",
"cn-beijing": "https://atp-modelzoo-bj.oss-cn-beijing-internal.aliyuncs.com/release/tutorials/llama2/llama2-7b.tar.gz",
}
path = url_link[dsw_region]
os.environ['link_CHAT'] = path
!wget $link_CHAT
!tar -zxvf llama2-7b.tar.gz
如果您的地区不在上述地区中,您可以自行选择与你地域最近的链接进行下载(不同地域不共享内网,记得将链接中的-internal去掉)。同一地域的数据下载速度快,不同地域之间也可以下载,但是速度比同一地域略慢。
如果您希望从ModelScope下载模型,请点击链接:https://modelscope.cn/models/modelscope/Llama-2-7b-chat-ms/summary
2、下载和安装环境
接着下载和安装所需要的环境。
ColossalAI是大规模并行AI训练系统,在本例中我们使用该框架进行模型微调。transformers是基于transformers模型结构的预训练语言库。gradio是一个快速构建机器学习Web展示页面的开源库。
! wget https://atp-modelzoo-sh.oss-cn-shanghai.aliyuncs.com/release/tutorials/llama2/ColossalAI.tar.gz
! tar -zxvf ColossalAI.tar.gz
! pip install ColossalAI/.
! pip install ColossalAI/applications/Chat/.
! pip install transformers==4.30.0
! pip install gradio==3.11
3、下载示例训练数据
下载训练所需的数据,这里我们提供的一份创意生成数据,包括发言稿生成等内容。
您也可以参考该格式,自行准备所需数据。
! wget https://atp-modelzoo-sh.oss-cn-shanghai.aliyuncs.com/release/tutorials/llama2/llama_data.json
! wget https://atp-modelzoo-sh.oss-cn-shanghai.aliyuncs.com/release/tutorials/llama2/llama_test.json
三、微调模型
您可以使用已经写好的训练脚本,进行模型训练。
! sh ColossalAI/applications/Chat/examples/train_sft.sh
四、试玩模型
模型训练完成后,下载我们提供的webUI demo,试玩微调完成的模型(注意模型地址替换为自己训练好的模型地址)。
import gradio as gr
import requests
import json
from transformers import AutoTokenizer, AutoModelForCausalLM
#模型地址替换为自己训练好的模型地址
tokenizer = AutoTokenizer.from_pretrained("/mnt/workspace/sft_llama2-7b",trust_remote_code=True)
#模型地址替换为自己训练好的模型地址
model = AutoModelForCausalLM.from_pretrained("/mnt/workspace/sft_llama2-7b",trust_remote_code=True).eval().half().cuda()
def inference(text):
from transformers import pipeline
pipe = pipeline("text-generation", model=model, tokenizer=tokenizer,device='cuda:0', max_new_tokens=400)
res=pipe(text)
return res[0]['generated_text'][len(text):]
demo = gr.Blocks()
with demo:
input_prompt = gr.Textbox(label="请输入需求", value="请以软件工程师的身份,写一篇入职的发言稿。", lines=6)
generated_txt = gr.Textbox(lines=6)
b1 = gr.Button("发送")
b1.click(inference, inputs=[input_prompt], outputs=generated_txt)
demo.launch(enable_queue=True, share=True)
五、模型上传至OSS并在线部署
如果希望将上述模型部署至PAI-EAS,您需要首先将训练完成的模型上传至OSS。
下列参数需要根据您自己的信息填写
# encoding=utf-8
import oss2
import os
AK='yourAccessKeyId'
SK='yourAccessKeySecret'
endpoint = 'yourEndpoint'
dir='your model output dir'
auth = oss2.Auth(AK, SK)
bucket = oss2.Bucket(auth, endpoint, 'examplebucket')
for filename in os.listdir(dir):
current_file_path = dir+filename
file_path = '需要上传地址'
bucket.put_object_from_file(file_path, current_file_path)
接下来进行部署工作,步骤请参考【最佳实践三:Llama2 快速部署 WebUI】
最佳实践三:Llama2 快速部署 WebUI
? 本实践将采用阿里云机器学习平台PAI-EAS 模块针对 Llama-2-13B-chat 进行部署。PAI-EAS是模型在线服务平台,支持将模型一键部署为在线推理服务或AI-Web应用,具备弹性扩缩的特点,适合需求高性价比模型服务的开发者。
一、服务部署
1、 进入PAI-EAS模型在线服务页面。
a.登录PAI控制台 https://pai.console.aliyun.com/
b.在左侧导航栏单击工作空间列表,在工作空间列表页面中单击待操作的工作空间名称,进入对应工作空间内。
c.在工作空间页面的左侧导航栏选择模型部署>模型在线服务(EAS),进入PAI EAS模型在线服务页面。
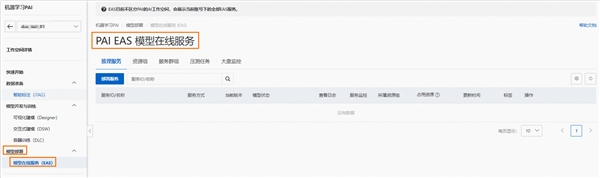
2、在PAI EAS模型在线服务页面,单击部署服务。
3、在部署服务页面,配置以下关键参数。
|
参数 |
描述 |
|
服务名称 |
自定义服务名称。本案例使用的示例值为:chatllm_llama2_13b。 |
|
部署方式 |
选择镜像部署AI-Web应用。 |
|
镜像选择 |
在PAI平台镜像列表中选择chat-llm-webui,镜像版本选择1.0。 由于版本迭代迅速,部署时镜像版本选择最高版本即可。 |
|
运行命令 |
服务运行命令: 如果使用13b的模型进行部署:python webui/webui_server.py --listen --port=8000 --model-path=meta-llama/Llama-2-13b-chat-hf --precision=fp16如果使用7b的模型进行部署:python webui/webui_server.py --listen --port=8000 --model-path=meta-llama/Llama-2-7b-chat-hf端口号输入:8000 |
|
资源组种类 |
选择公共资源组。 |
|
资源配置方法 |
选择常规资源配置。 |
|
资源配置选择 |
必须选择GPU类型,实例规格推荐使用ecs.gn6e-c12g1.3xlarge。 13b的模型务必跑在gn6e及更高规格的机型上。 7b的模型可以跑在A10/GU30机型上。 |
|
额外系统盘 |
选择50GB |
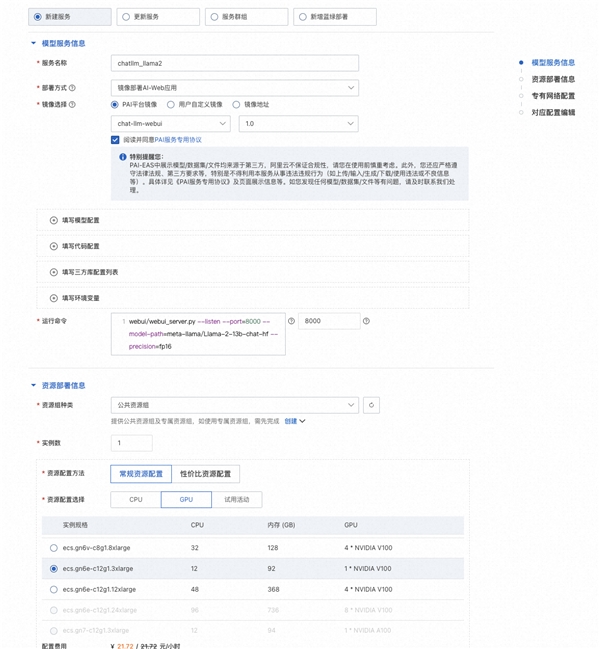
4、单击部署,等待一段时间即可完成模型部署。
二、启动WebUI进行模型推理
1、单击目标服务的服务方式列下的查看Web应用。
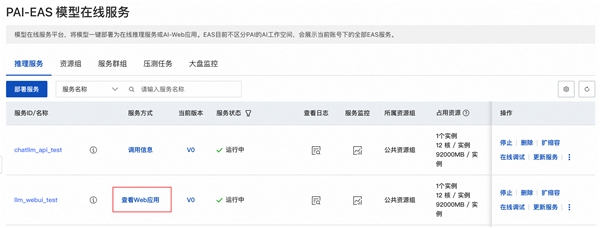
2、在WebUI页面,进行模型推理验证。
在对话框下方的输入界面输入对话内容,例如”请提供一个理财学习计划”,点击发送,即可开始对话。
What's More
1.本文主要展示了基于阿里云机器学习平台PAI快速进行Llama2微调及部署工作的实践,主要是面向7B和13B尺寸的。后续,我们将展示如何基于PAI进行70B尺寸的 Llama-2-70B 的微调及部署工作,敬请期待。
2.上述实验中,【最佳实践三:Llama2 快速部署 WebUI】支持免费试用机型运行,欢迎点击【阅读原文】前往阿里云使用中心领取“PAI-EAS”免费试用后前往PAI控制台体验。
参考资料:
Llama2: Inside the Model https://ai.meta.com/llama/#inside-the-modelLlama 2 Community License Agreement https://ai.meta.com/resources/models-and-libraries/llama-downloads/HuggingFace Open LLM Leaderboard https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard阿里云机器学习平台PAI:https://www.aliyun.com/product/bigdata/learn
特别提示您 Llama2 属于国外公司开发的限制性开源模型,请您务必在使用前仔细阅读并遵守 Llama2 的许可协议,尤其是其限制性许可条款(如月活超过7亿以上的企业需申请额外许可)和免责条款等。
此外提醒您务必遵守适用国家的法律法规,若您利用 Llama2 向中国境内公众提供服务,请遵守国家的各项法律法规要求,尤其不得从事或生成危害国家、社会、他人权益等行为和内容。



