
IT采购网4月20日消息,英伟达和康奈尔大学的研究团队合作,近日推出了名为 VideoLDM 模型,可以根据文本描述,自动生成最高分辨率2048*1280、24 帧、最长 4.7 秒的视频。据悉,该模型配有 41 亿个参数,其中 27 亿个经过视频训练,这符合现代生成式 AI的标准。英伟达表示通过高效的潜在扩散模型(LDM),能够创建多样化、高质量、高清晰度的视频。
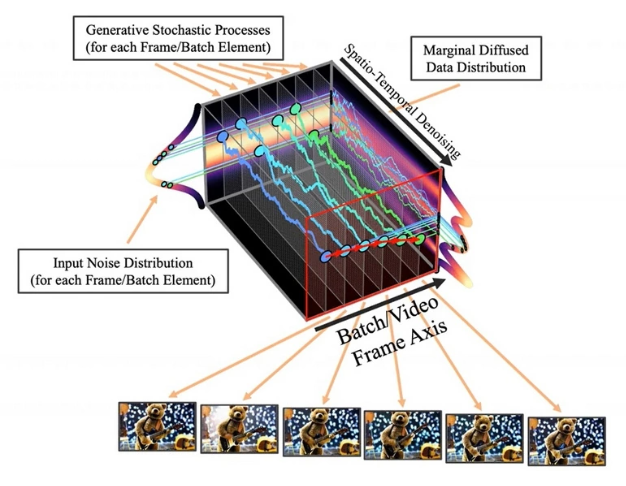
该模型还能创建驾驶场景的视频,视频分辨率为 1024 × 512 像素,最长 5分钟。目前该项目处于研究阶段,暂时不会向公众开放。如果成功地推出并商业化,这项技术可能会有广泛的应用,例如在电影制作、虚拟现实、自动驾驶等领域。然而,对于一些应用场景,如社交媒体和在线广告等,需要考虑到潜在的伦理和法律问题,例如虚假信息传播和侵犯隐私等。

据IT采购网了解,VideoLDM是一项令人兴奋的技术,它利用了深度学习技术中的生成式模型来生成视频。该模型的训练需要大量的数据和计算资源,并且需要专业的技能和经验来构建和调整模型参数。因此,该技术目前还处于研究阶段,需要更多的测试和改进,以实现更好的性能和应用。总之,VideoLDM技术展示了深度学习技术在生成式任务中的潜力,它将有望在未来的技术创新和应用中发挥重要作用。



